I spent the last few days at a technical workshop where I spoke about Agile and DevOps and while preparing my talks I did a bit of reflection. What I realised is that my story towards my current level of understanding might be a good illustration of the challenges and solutions we have come up with so far. Of course everyone’s story differs, but this is mine and sharing it with the community might help some people who are on the journey with me.
As a picture speaks more than a thousand words, here is the visual I will use to describe my journey.
(Note: The Y-axis shows success or as I like to call it the “chance of getting home on time”, the X-axis is the timeline of my career)
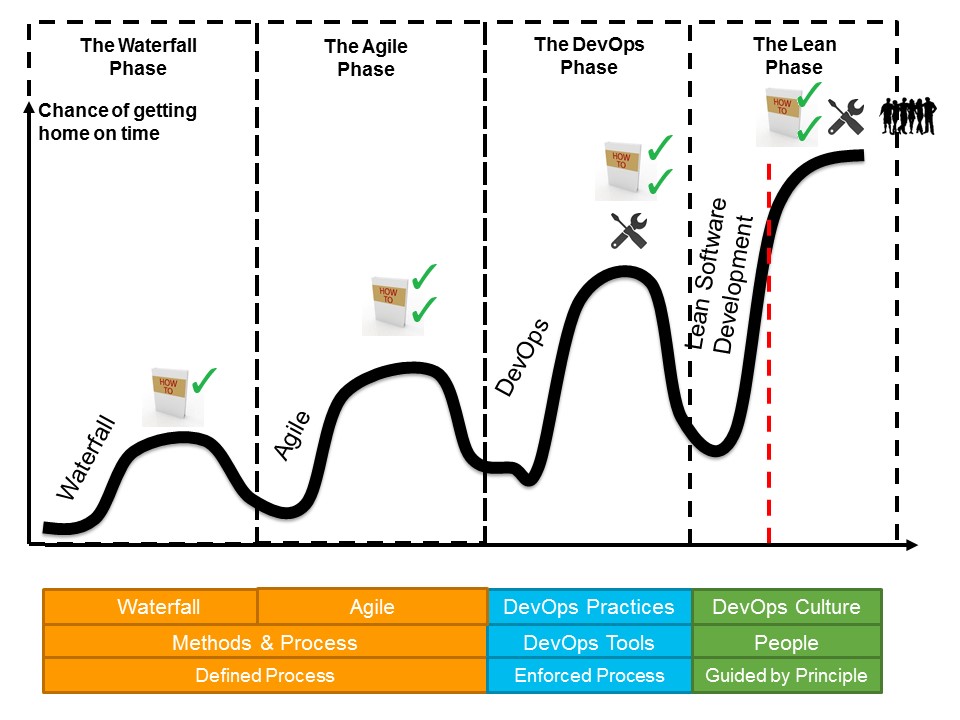
The Waterfall Phase – a.k.a. the Recipe Book
When I joined the workforce from university and after doing some research into compilers, self-driving cars and other fascinating topics that I was allowed to explore in the IBM research labs, I was immediately thrown into project work. And of course as was custom I went to corporate training and learned about our waterfall method and the associated process and templates. I was amazed, project work seemed so simple. I got the methodology, processes and templates and all I have to do was following them. I set out to master this methodology and initial success followed the better I got at it. I had discovered the “recipe book” for success that described exactly how everyone should behave. Clearly I was off to a successful career.
The Agile Phase – a.k.a. A Better Recipe Book
All was well, until I took on a project for which someone else created a project plan that saw the project completed in 12 weeks’ time. I inherited the project plan and Gantt chart and was off to deliver this project. Very quickly it turned out that the requirements were very unclear and that even the customer didn’t know everything that we needed to know to build a successful solution. The initial 4 weeks went by and true to form I communicated 33% completion according to the timeline even though we clearly didn’t make as much progress as we should. Walking out of the status meeting I realised that this could not end well. I setup a more informal catch-up with my stakeholders and told them about the challenge. They agreed and understood the challenge ahead and asked me what to do. Coincidence came to my rescue. On my team we had staffed a contractor who had worked with Agile before and after a series of coffees (and beers for that matter) he had me convinced to try this new methodology. As a German I lived very much up to the stereotype as I found it very hard to let go of my beloved Gantt charts and project plans and the detailed status of percentage complete that I had received from my team every week. Very quickly we got into a rhythm with our stakeholders and delivered increments of the solution every two week. I slowly let go of some of the learned behaviour as waterfall project manager and slowly became a scrum master. The results were incredible, the team culture changed, the client was happier and even though we delivered the complete solution nowhere close to the 12 weeks (in fact it was closer to 12 months), I was convinced that I found a much better “recipe book” than I had before. Clearly if everyone followed this recipe book, project delivery would be much more successful.
The DevOps Phase – a.k.a. the Rediscovery of Tools
And then a bit later another engagement came my way. The client wanted to get faster to market and we had all kind of quality and expectation setting issues. So clearly the Agile “recipe book” would help again. And yes, our first projects were a resounding success and we quickly grew our Agile capability and more and more teams and projects adopted Agile. It however quickly became clear that we could not reduce the time to market as much as we liked and often the Agile “recipe book” created a kind of cargo cult – people stood up in the morning and used post-its and consider themselves successful Agile practitioners. Focusing on the time to market challenge I put a team in place to create the right Agile tooling to support the Agile process through an Agile Lifecycle Management system and introduced DevOps practices (well back then we didn’t call it DevOps yet). The intention was clear, as an engineer I thought we could solve the problem with tools and force people to follow our “recipe book”. Early results were great, we saved a lot of manual effort, tool adoption was going up, and we could derive status from our ALM. In short, my world was fine. I went off to do something different. Then a while later I came back to this project and to my surprise the solution that I put in place earlier had deteriorated. Many of the great things I put in place had disappeared or had changed. I wanted to understand what happened and spent some time investigating. It turned out that the people involved made small decisions along the way that slowly slowly lost sight of the intention of the tooling solution and the methodology we used. No big changes, just a death by a thousand cuts. So how am I going to fix this one…
The Lean Phase – a.k.a. Finally I Understand (or Think I do for Now)
Something that I should have known all along became clearer and clearer to me: Methodology and tools will not change your organisation. They can support it but culture is the important ingredient that was missing. As Drucker says: “Culture eats strategy for breakfast”. It is so very true. But how do you change culture… I am certainly still on this journey and cultural change management is clearly the next frontier for myself. I have quickly learned that I need to teach people the principles behind Agile and DevOps, which includes a elements of Lean, Systems Thinking, Constraint Theory, Product Development Flow and Lean Startup thinking. But how do I really change the culture of an organisation, how do I avoid the old saying that “to change people, you sometimes have to change (read replace) people”. As an engineer I am pretty good with the process, tools and methodology side, but the real challenge seems to lie in the organisational change management and organisational process design. And I wonder whether this is really the last frontier and or will there be a next challenge right after I have mastered this one…
The good news is that many of us are on this journey together, and I am confident that on the back of the great results we achieved with tools and methodology alone, truly great things lie ahead of us still as we master the cultural transformation towards becoming DevOps organisations.










{kind=link}