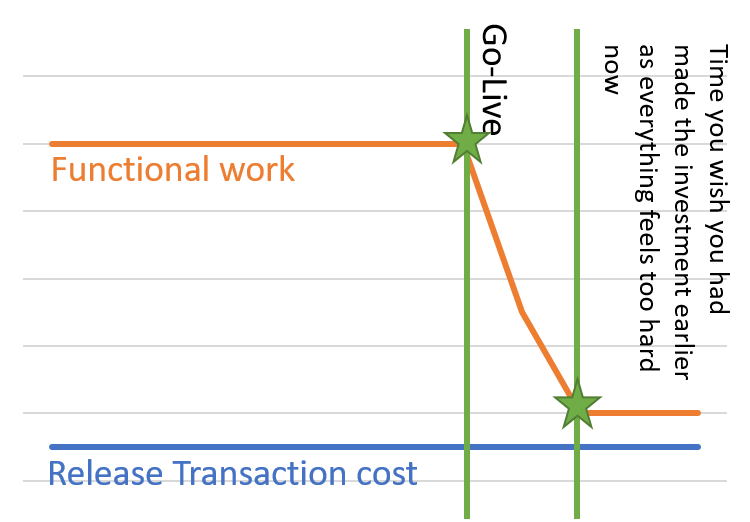
I am not really objective when I say that I hope you have read the most recent Guide to Continuous Delivery Vol. 3 as I had the honor to contribute an article to it. My article is about mapping out a roadmap for your DevOps journey and I have an extended and updated blog article in draft on that topic that I will push out sometime soon. There is a lot of really good insight in this guide and for the ones with little time or who just prefer the “CliffsNotes”, I want to provide my personal highlights. I won’t go through every article but will cover many of them. Besides articles the guide provides a lot of information on tooling that can help in your DevOps journey.
I am not really objective when I say that I hope you have read the most recent Guide to Continuous Delivery Vol. 3 as I had the honor to contribute an article to it. My article is about mapping out a roadmap for your DevOps journey and I have an extended and updated blog article in draft on that topic that I will push out sometime soon. There is a lot of really good insight in this guide and for the ones with little time or who just prefer the “CliffsNotes”, I want to provide my personal highlights. I won’t go through every article but will cover many of them. Besides articles the guide provides a lot of information on tooling that can help in your DevOps journey.
Key Research Findings
The first article covers the CD survey that was put together for this guide. While less people said they use CD this might indicate more people understanding better what it takes to really do CD, I take this a positive indication for the community. Unsurprisingly Docker is very hot, but its clear that there is a long way to go to make it really work when you look at the survey results.
Five Steps to Automating Continuous Delivery Pipelines
Very decent guidance on how to create your CD pipeline, the two things that stood out for me are “Measure your pipeline”, which is absolutely critical to enable continuous improvement and potentially crucial for measuring the benefits for your CD business case. It also highlights that you sometimes need to include manual steps, which is where many tools fall down a bit. Gradually moving from manual to full automation by enabling a mix of automated and manual steps is a very good way to move forward.
Adding Architectural quality metrics to your cd pipeline
An interesting article on measuring more than just functional testing in your pipeline. It stresses the point to include performance and stress testing in the pipeline and that even without full scale in early environments you can get good insights from measuring performance in early environments and use the relative change to investigate areas of concern.
There is other information that can provide valuable insights into architectural weaknesses like # of calls to external systems, response time and size for those calls, number of exceptions and CPU time.
How to Define your DevOps roadmap – Well read the whole article 😉
Four Keys to Successful Continuous Delivery
Three of the keys are quite common: Culture, Automation and Cloud. What I was happy to see what the point about open and extendable tools. Hopefully over time more vendors realise that this is the right way to go.
A scorecard for measuring ROI of Continuous Delivery Investment
An interesting short model for measuring ROI, it uses lots of research based numbers as inputs into the calculations. Could come in handy for some who want a high-level business case.
Continuous Delivery & Release Automation for Microservices
I really liked this article with quite a few handy tips for managing Microservices that match my ideas to a large degree. For example you should only get into Microservices if you already have decent CI and CD skills and capabilities. Microservices require more governance than traditional architectures as you will likely deal with more technology stacks, have to deal with additional testing complexity and require a different ops model. To deal with this you need to have a real-time view of status and dependencies of your Microservices. The article goes into quite some detail and provides a nice checklist.
Top CD resources
No surprise here to see the State of DevOps report, Phoenix Project and the Continuous Delivery book on this list.
Make sure to check out the DevOps Checklist on devopschecklist.com – there is lots of good questions on this checklist that can make you think about possible next steps for your own adoption.
Continuous Delivery for Containerized Applications
A lot of common ground get revisited in this article like the need for immutable Microservices/containers, Canary launches and A/B testing. What I found great about this article is the description of a useful tagging mechanism to govern your containers through the CD pipeline.
Securing a Continuous Delivery Pipeline
Some practical guidance on leveraging the power of CD pipelines to increase security, a topic that was just discussed at the DevOps Forum in Portland too and which means we should see some guidance coming out later in the year. The article highlights that tools alone will not solve all your problems but can provide real insights. When starting to use tools like SonarQube be aware that the initial information can be confusing and it will take a while to make sense of all the information. Using the tools right will allow you to free up time for more meaningful manual inspections where required.
Executive Insights on Continuous Delivery
Based on interviewing 24 executives this articles gathers their insights. Not surprisingly they mention that it is much easier to start in a green fields environment than in brown fields. Even though everyone agrees that tools have significantly improved, the state of CD tools is still not where people would like it to be and many organisations still have to create a lot of homemade automation. The “elephant in the room” that is raised at the end is that in general people rely on intuition still for the ROI of DevOps, there is no obvious recommendation for how to measure this scientifically.
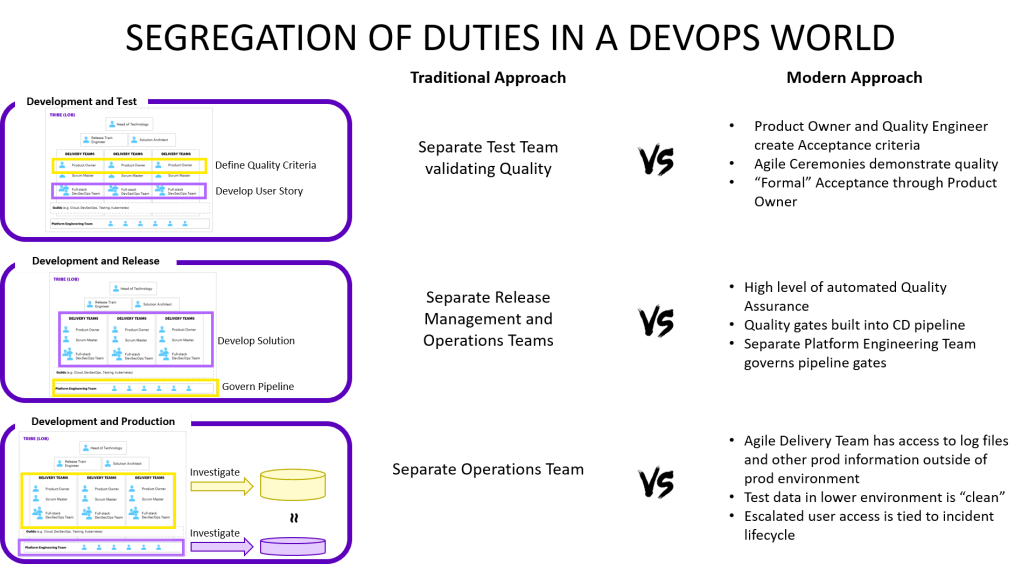





 I am trying something new with this blog post – providing a mix of book review and a summary of what I learned about a book I really like. Waiting for Mark Schwartz to release his latest book “War and Peace and IT” I thought I re-read his earlier works. And as I was reading “The Art of Business Value” again I noticed that I am reading it with fresh eyes and that I appreciate this book even more than a few years ago.
I am trying something new with this blog post – providing a mix of book review and a summary of what I learned about a book I really like. Waiting for Mark Schwartz to release his latest book “War and Peace and IT” I thought I re-read his earlier works. And as I was reading “The Art of Business Value” again I noticed that I am reading it with fresh eyes and that I appreciate this book even more than a few years ago. There are obviously a few things different with this transformation and the most obvious yet confusing thing is that there is no end-state. There is no end-state technology architecture, there is no end-state organisational structure and there is no end-state delivery methodology. But if there is no end-state how do we know when we are done? This is the bad news, we will never be done. We have to create capabilities that make it easier and easier to adapt incrementally and we need mechanisms to guide each improvement even in the absence of an end-state.
There are obviously a few things different with this transformation and the most obvious yet confusing thing is that there is no end-state. There is no end-state technology architecture, there is no end-state organisational structure and there is no end-state delivery methodology. But if there is no end-state how do we know when we are done? This is the bad news, we will never be done. We have to create capabilities that make it easier and easier to adapt incrementally and we need mechanisms to guide each improvement even in the absence of an end-state.