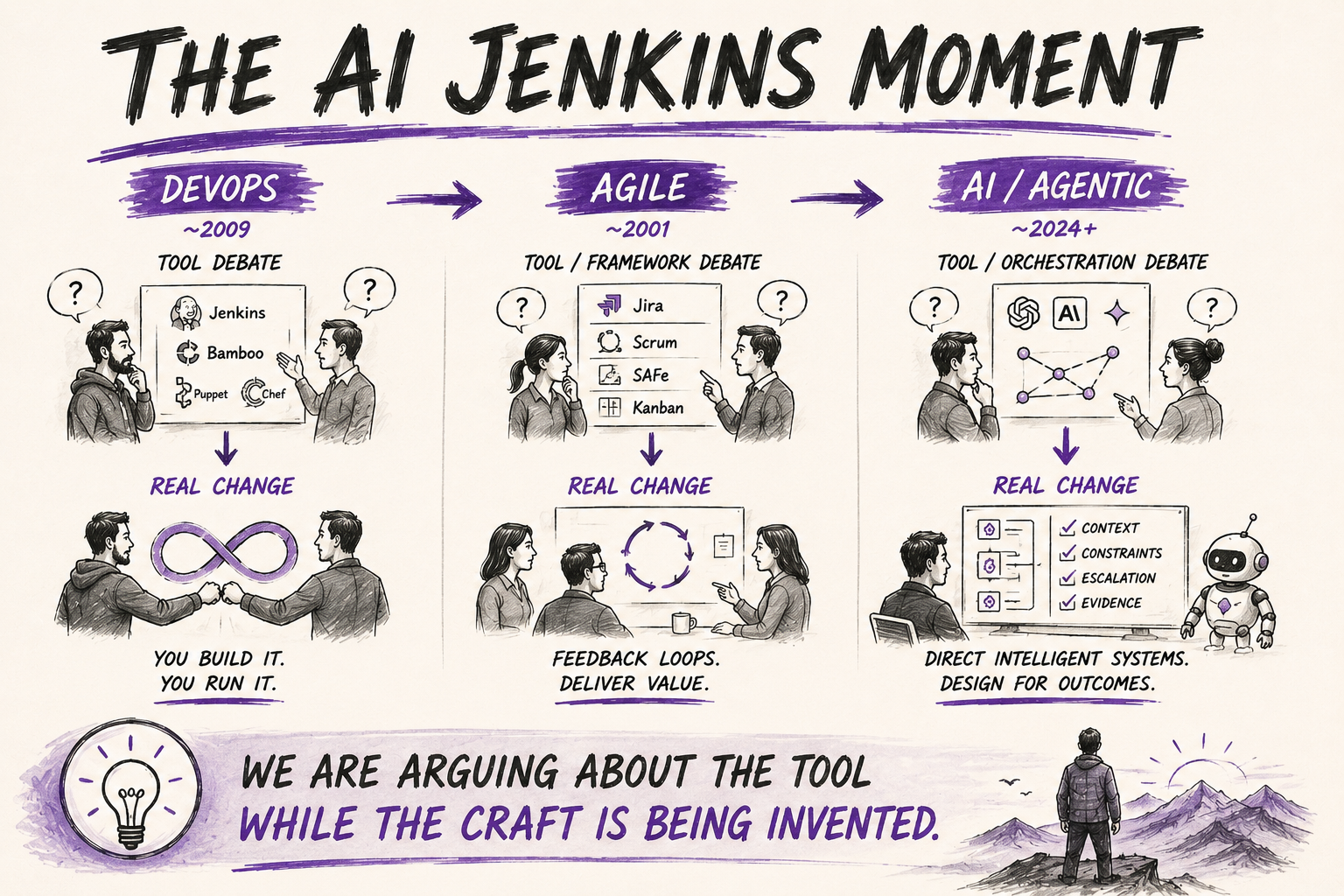
When you heat metal and cool it slowly, its internal stresses are relieved. The internal structure settles into a more stable state.
This is annealing, and I think it is a useful way to think about software architecture when AI agents are doing part of the delivery work.
Hot and cold are not just descriptions. They are controls.
A hot zone is one where change is permitted, cheap and expected. A cold zone is one where the structure has been deliberately locked. Temperature is not something the code naturally possesses. It is a choice the team makes and then enforces through permissions, repository boundaries, tool access, testing and approval paths.
That kind of graduated control becomes important when agents are the ones making changes.
Most software architecture practices assume that everything is modifiable in principle. Given the right people, the right process and enough time, any part of a system can be changed.
Architecture evolves. It has always been expensive, but it has also been manageable because humans controlled the pace.
AI delivery changes that.
When agents can propose changes, write code and modify configuration faster than any human review process can follow, the question of what they can reach becomes urgent.
Anything within reach becomes a candidate for change in pursuit of the objective the agent has been given. An agent does not intuitively distinguish between a throwaway utility function and the data model that forty other services depend on. If both are in scope, both are available.
The tempting response is to make the entire architecture fair game and trust the AI to find the right shape.
The first problem is comprehensibility. If agents have been free to touch everything, you can end up with an architecture whose design intent nobody can reconstruct. It may work perfectly well. The problem is that no human was accountable for the structure as a whole. You own something you cannot properly explain.
The other problem is economic. The more of the architecture an agent must consider, the more context it needs. That means more tokens, slower reasoning, higher cost and more opportunities for important details to be missed.
An architecture with no cold zones is not only difficult to govern. It is expensive to operate.
The response is to make architecture “temperature” choices explicit.
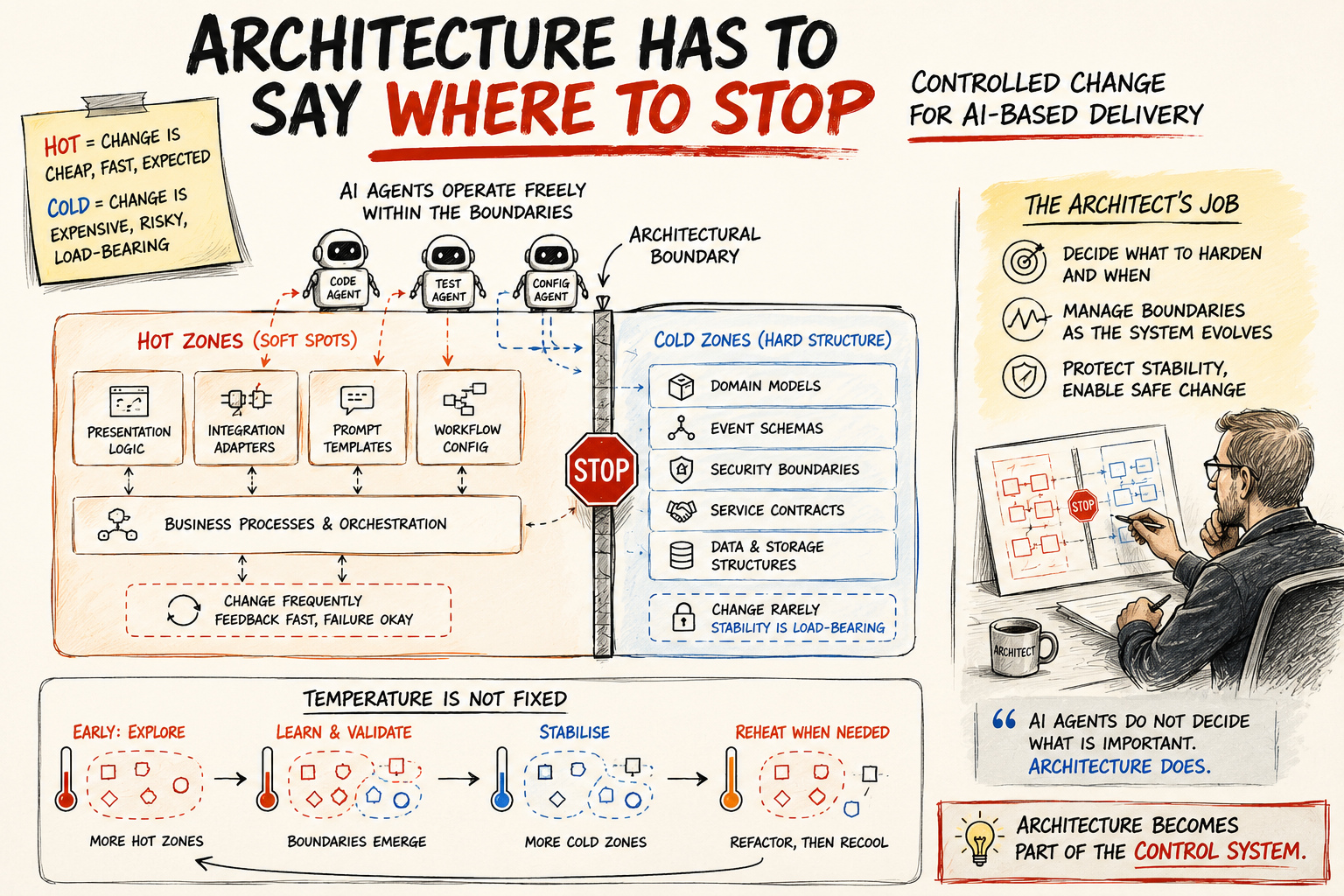
Some parts of an architecture should run hot.
These are places where change is cheap, feedback is fast and the cost of a wrong move is low. Presentation logic. Integration adapters. Prompt templates. Workflow configuration.
These are the soft spots. They are deliberately kept malleable so that agents can work freely. Their structure is not expected to last. It should be shaped and reshaped as requirements shift and models improve.
Other parts should run cold.
These are decisions with a wide blast radius, many dependants or serious security and regulatory consequences. Domain models. Event schemas. Security boundaries. Contracts between services.
Once these structures have proved themselves, they should crystallise intentionally. The cost of changing them is high, and their stability is load-bearing.
Agents do not modify cold zones. They work within them.
These classifications are not permanent. A domain model may run hot while a team is still discovering it. It cools as the design stabilises and more of the system comes to depend on it.
The hard work is managing that change in temperature.
You need to decide what to harden and when. Sometimes a cold zone must be reheated for a major refactor, then cooled again once the new structure has been established. Early in delivery, more of the system can remain hot while the team learns what the architecture needs to become. As the structure proves itself, the temperature comes down.
I first came across this idea while studying AI at Edinburgh University many years ago.
Simulated annealing is a classical optimisation technique. It runs hot early so that the algorithm can explore broadly, then cools gradually as it converges on a solution.
Here, the same idea is being applied in the other direction. It is not a technique inside the AI system. It is a governance model for the systems that AI is allowed to change.
None of this is entirely new.
Domain-driven design, intentional architecture and event sourcing all try, in different ways, to separate the things that change from the things that need to remain stable.
What changes with AI is the speed and autonomy of the actor.
An agent does not slow down when it reaches a part of the codebase that looks important. It does not become cautious because a change has political, operational or architectural consequences. If the change is within its permissions and appears to support its objective, it will make it.
The discipline that once lived mainly in code review and architectural governance now needs to be built into the system itself.
The teams that get this right will not necessarily be the ones with the best models or the most sophisticated orchestration. They will be the ones that can read the temperature of their architecture: where agents should be free to explore, where they must stop, and when those boundaries need to move.
AI-native architecture is not simply about making systems easier for agents to change.
It is about controlling where change is allowed, how quickly it can happen, and when the boundaries themselves need to move.
The architecture becomes part of the control system.