
It’s over again. The annual DevOps family reunion in San Francisco. This year was extra special because I feel I learnt even more than in previous years and because I was able to hand out preview copies of my upcoming book. I am really looking forward to hear from those of you who got a copy what you think. Reach out and let me know. I will talk a little bit about the book in an upcoming blog post.
The summit had a lot more variety of topics than previous years (at least the talks I attended), which I found very refreshing. Technology talks, culture talks, security, case studies, agile – so many different perspectives on IT transformation. Congratulations to the program committee for getting such a good mix and balance.
So let’s recap what I have learned from the summit.
Keybank presentation
This was clearly one of my highlights. Hearing from a bank which is using microservices and the Netflix OSS to stabilise environments was great. To then hear they were able to outperform expectations and delivery faster and with increased scope, just shows what is possible when you get this right. Well done team and looking forward to hear more in the upcoming years. They mentioned one really interesting ideas that I will take away from the conference: “It is not a reason not to automate something if you don’t do it frequently. In fact you should automate in those cases as you don’t get a lot of practice at it.” I will remember this.
John Allspaw
Of course the expectations on my side were high when I saw John will speak. And boy did he deliver. A fascinating talk about how we cannot see what we do directly but rather work with models in our head and manipulate it via a keyhole – the screen – to interact with the invisible system. This makes you think. It requires us to move from incidents as motivators for policy – towards incidents as messages of the invisible system to us that we should use to update the mental model. Incidents show where the models are misaligned. This is tricky to operationalise and speaks to us as individuals.
We should then look at incidents as unplanned investments where the cost is already fixed for us – so how do we maximise the ROI on it? Commonly Post Mortems value the actions items at the end, but more important is the updated mental model we should have at the end. Questions to ask beyond “What went wrong?” and “How did it break?” We should talk about what made it not nearly as bad is could have been. And how can we continue to learn about the invisible systems. This talk created a lot of conversation over drinks. Mind Blown!
Scott Prugh and Erica Morrison from CSG
The continuation of the CSG story which is familiar to many of us. Good to hear they continue to challenge the status quo and push forward. The metric of the conference was “how much sleep do I get when we make changes” which moved from very little to a lot. It also showed the need to shift from a more dev focused devops to a more ops focused or balanced view and what it does to the incidents in production. And of course we might never forget Scott with a sledgehammer destroying mode 1 once and for all…
Columbia’s Scott Nasello
A story of just getting on with it and doing the right thing to improve the situation. Not a transformation with funding etc. A good reminder of what can be done if you really want to do something. The stories around Configuration management as foundation to everything – from emailing scripts to proper SCM – sound very close to some of the things I have experienced. And then the innovative approach of swapping people out regularly to create that constant beginner mindset that allows you to question things and to learn new things. Really interesting approach.
And of course the coolest random fact: It takes only 29 dominoes to take down the empire state building. Yes really!
Damon Edwards
I liked this presentation just like all the other ones that Damon has done. A good reminder that Ops is more than deployments and pipelines. I liked the insight that ticket driven queues are a sign for silos in your org. And that tickets should be for exceptions not for actual work. He went on to define Ops as a service – definition of automated procedure, execution of it and governance – which is a framework I will surely use in the future. Thanks Damon.
Amazon
This was a good industry story of the need for immediacy and how this will continue to increase. They had to learn how to integrate across multiple teams and how you need have teams that look after the end to end business service. I also learned a new word: “hyperconvenience”
Disney – Jason Cox
Phew – Finally I could attend a full talk from Jason – yay! Of course the videos were awesome and a Star Wars trailer always gets my full attention. I could very much relate to the analogy of “corporate” services perceived as the empire. Even though all you want to do is help the team and how they had to overcome this perception. I also really liked the technology rotation program for managers to continually challenge the status quo and build empathy across the business. And of course I wish I could call my training program “Jedi Engineering Training Academy” – best name ever for a training program 😉
Pivotal – Cornelia Davis
Really good semi technical talk about cloud native applications – I will definitely will buy her book. She spoke about:
- Dynamic load balancing
- Statelessness in the architecture
- Application lifecycle – events have rippling effects – you need to ping and deal with it automatically
- Versioned services and deployment in parallel not replacement of services
- Dynamically updated router for service discovery or a dedicated server to manage it
- Data APIs and caching is important to decouple from database
- Or a database per microservice and event driven data propagation, commonly using kafka as unified log and universal source of truth
Nicole Forsgren
The queen of DevOps data did not disappoint. Nicole went through 4 years of learnings. Most importantly how throughput and stability move together and are not a tradeoff.
That you should use MTTR, lead time to change and deployment frequency as good measure to understand improvements. And that when you improve DevOps performances it is likely to improve organisational performance. Nicole also shares my scepticism about maturity models which are aging too fast due to changes in capabilities. I think they can still be useful in the right hands, but one has to be careful. In a room full of techies she challenged us with “Tech plus”: It takes IT combined with other things to make companies successful.
Her litmus test for DevOps success: “can you deploy on demand, independently and during business hours?” And if you don’t know where to start, take her advice and look at Architecture, Continuous Integration and a lightweight change approval process as good starting points
Unfortunately I could not attend the third day of the conference, but I will surely catchup on the videos later. I will certainly be back next year and look forward to hear what everyone else learned this year.
Thanks Gene, Thanks organising team, thanks DevOps family – looking forward to see all you brothers, sisters and cousins at the next family gathering with Papa Gene 😉
 I guess it is time to get back to work. This week I will shift my focus away from teaching my son how to build block towers, how to not kill himself while climbing on and falling off furniture and other required survival skills. I will go back into the complex and exciting world of Agile and DevOps, but before I do this I wanted to share what my paternity time meant for me.
I guess it is time to get back to work. This week I will shift my focus away from teaching my son how to build block towers, how to not kill himself while climbing on and falling off furniture and other required survival skills. I will go back into the complex and exciting world of Agile and DevOps, but before I do this I wanted to share what my paternity time meant for me.
 When I saw a physical copy of the book for the first time in the morning, it was an unreal feeling. There was certainly pride but also a level of disbelief. But damn does it look good 😉 I went on to an interview with Alan Shimmel (which you can find
When I saw a physical copy of the book for the first time in the morning, it was an unreal feeling. There was certainly pride but also a level of disbelief. But damn does it look good 😉 I went on to an interview with Alan Shimmel (which you can find 



 Happy New year to you all. I am now half-way through my paternity leave and I will have to admit that the “Father of the year” award might be slightly out of reach for me this year. I will get to that, but first let me tell you that I will write to the government and make it clear that this should not be called paternity leave. It is paternity work. I have so much respect for all those full-time parents, your day is fully organised by eating, putting little one to bed, cleaning up, making food, changing baby,… I am keeping up with the schedule but will admit that my wife sent me some handy SMS reminders during the day in the beginning. And then you need to use the few free moments to get the basics done: Shower, eat, check on the Ashes and soccer results,…
Happy New year to you all. I am now half-way through my paternity leave and I will have to admit that the “Father of the year” award might be slightly out of reach for me this year. I will get to that, but first let me tell you that I will write to the government and make it clear that this should not be called paternity leave. It is paternity work. I have so much respect for all those full-time parents, your day is fully organised by eating, putting little one to bed, cleaning up, making food, changing baby,… I am keeping up with the schedule but will admit that my wife sent me some handy SMS reminders during the day in the beginning. And then you need to use the few free moments to get the basics done: Shower, eat, check on the Ashes and soccer results,…
 After writing about behaviours that help new joiners to be successful I finally got around to write about managers. What does a successful manager look like. And here I don’t mean specific practices like the ones you can learn from
After writing about behaviours that help new joiners to be successful I finally got around to write about managers. What does a successful manager look like. And here I don’t mean specific practices like the ones you can learn from  The good news first: our little one is still alive 😉 All the abstract talk about being a full-time dad has now become my reality. We do not have family around us here as our families live in Sri Lanka and Germany respectively, so there is not a lot of help available. I have been pretty hands-on before as well, getting the little man to sleep, making him food and feeding him and of course changing lots of, let’s say smelly, diapers. But that has been nothing in comparison with being a full time dad.
The good news first: our little one is still alive 😉 All the abstract talk about being a full-time dad has now become my reality. We do not have family around us here as our families live in Sri Lanka and Germany respectively, so there is not a lot of help available. I have been pretty hands-on before as well, getting the little man to sleep, making him food and feeding him and of course changing lots of, let’s say smelly, diapers. But that has been nothing in comparison with being a full time dad. time meeting many of my colleagues and looking around the modern office. Of course his daily routine got disrupted by our little adventure. So far I am enjoying the experience and the world at work is not coming to an end. It was a slow letting go of work as I spoke to someone at work every day. Next week I will hear less from work I think. Let’s see. The weather is certainly incentivising me to spend more time outside in parks and cafes, that’s a performance objective I am happy to work on…
time meeting many of my colleagues and looking around the modern office. Of course his daily routine got disrupted by our little adventure. So far I am enjoying the experience and the world at work is not coming to an end. It was a slow letting go of work as I spoke to someone at work every day. Next week I will hear less from work I think. Let’s see. The weather is certainly incentivising me to spend more time outside in parks and cafes, that’s a performance objective I am happy to work on…


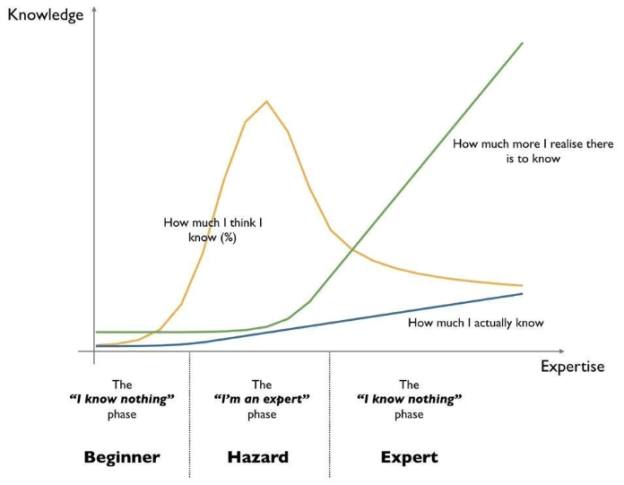
 Barry O’Reilly spoke about the Lean Enterprise – Overall a great and entertaining talk. The one thing that stood out to me was the “delivery gap” which just shows how bad companies are in evaluating themselves – and for that matter how bad people are evaluating themselves ( remember Dunning-Kruger effect).
Barry O’Reilly spoke about the Lean Enterprise – Overall a great and entertaining talk. The one thing that stood out to me was the “delivery gap” which just shows how bad companies are in evaluating themselves – and for that matter how bad people are evaluating themselves ( remember Dunning-Kruger effect). Near religious wars have been fought over which IT product to choose for a project or business function. Should you use SalesForce, SAP or IBM? I am not a product person, but I have learned over time that just looking at the functionality is not sufficient anymore. It is very unlikely that an organisation will use the product As-Is and the application architecture the product is part of will continue to evolve. The concept of an end-state-architecture is just not valid anymore. Each component needs to be evaluated on the basis of how easy it is to evolve and replace. Which is why architecture and engineering play a much larger role than in the past. This puts a very different view on product choice. Of course the choice is always contextual and for each company and each area of business the decision might be different. What I can do though is to provide a Technology Decision Framework that helps you to think more broadly about technology choices. I wrote about DevOps tooling a while ago and you will see similar thinking in this post.
Near religious wars have been fought over which IT product to choose for a project or business function. Should you use SalesForce, SAP or IBM? I am not a product person, but I have learned over time that just looking at the functionality is not sufficient anymore. It is very unlikely that an organisation will use the product As-Is and the application architecture the product is part of will continue to evolve. The concept of an end-state-architecture is just not valid anymore. Each component needs to be evaluated on the basis of how easy it is to evolve and replace. Which is why architecture and engineering play a much larger role than in the past. This puts a very different view on product choice. Of course the choice is always contextual and for each company and each area of business the decision might be different. What I can do though is to provide a Technology Decision Framework that helps you to think more broadly about technology choices. I wrote about DevOps tooling a while ago and you will see similar thinking in this post.