I have been speaking over the last couple of years about the nature of DevOps and Agile transformations. It is in my view not possible to manage them with a simple As-Is To-Be approach as your knowledge of your As-Is situation is usually incomplete and the possible To-Be state keeps evolving. You will need to be flexible in your approach and need to use agile concepts. For successful Agility you need to know what your success measures are, so that you see whether your latest release has made progress or not (BTW something way too many Agile efforts forget). So what could these success measures look like for your transformation?
Well there is not one metric, but I feel we can come up with a pretty good balanced scorecard. There are 4 high level areas we are trying to improve: Business, Delivery, Operations and Architecture. Let’s double click on each:
Business: We are trying to build better solutions for our business and we know we can only do this through experimentation with new features and better insights. So what measures can we use to show that we are getting better at it.
Delivery: We want to streamline our delivery and get faster. To do that we will automate and simplify the process wherever possible.
Operations: The idea has moved from control to react, as operations deals with a more and more complex architecture. So we should measure our ability to react quickly and effectively.
Architecture: Many businesses are struggling with their highly monolithic architectures or with their legacy platforms. Large scale replacements are expensive, so evolution is preferred. We need some measures to show our progress in that evolution.
With that in mind here is a sample scorecard design:
I think with these 4 areas we can drive and govern a transformation successfully. The actual metrics used will a) depend on the company you are working in and b) evolve over time as you find specific problems to solve. But having an eye on all 4 areas will make sure we are not forgetting anything important and we notice when we overoptimize in one area and something else drops.
Next time I get the chance I will use a scorecard like this, of course implemented in a dashboarding tool so that it’s real time. 😉
I have been working in agile ways for many years now and many things have become a mantra for every new engagement: we have teams of 7 +/- 2 people, doing 2 weeks sprints and keep the teams persistent for the duration of the engagement. Sounds right, doesn’t it? But is it?
How do we know those things? Do we have science or do we just believe it based on the Agile books we have read and what people have told us? Over the last few weeks and months I have actively sought out differing opinions and research to challenge my thinking. I want to share some of this with you.
Team size
Agile teams are 5-9 people. Full stop. Right? There is some research from Rally from a while back that shows that smaller teams are having higher productivity and throughput than larger teams. Larger teams however have higher quality. So far so non-controversial. If quality is really important we want slightly larger teams and a higher percentage of quality focused people in the team. What really made me rethink was an interview that I heard with an Agile coach, where he described how having larger teams lead to better predictability of outcome. He made two arguments for that, one was quality as discussed above where lower quality leads to rework and in small teams that can really hurt predictability. The second one was the more obvious one, in small teams sickness, holidays or other events have a much larger impact and/or people might feel less able to take time off and burn-out. So with all this in mind perhaps slightly larger teams are overall better, they might be less productive but provide higher quality, are more predictable and more sustainable. Perhaps those qualities are worth the trade-off?
Persistent teams
Teams should be long-lasting so that they only have to run through the Forming-Storming-Norming-Performing cycle once and then they are good to go. Every change to the team is a disruption that causes a performance dip. So far the common wisdom. I have heard arguments for a change in thinking – the real game changer is dedication to a team. Being 100% assigned to one team at a time is more important than having teams that work together for a long period of time. Rally in their research found that dedicated people have a 2x factor of performance while long-standing teams have only 1.5x. This model will also allow for more flexibility with scarce skillset – people with those can dedicate themselves to a new team each sprint. I feel there is something that speaks for this argument but personally there is a probably a balance to be found between full persistency and frequent change, but at least we don’t have to feel bad when the context requires us to change the team setup.
Sprint/Iteration Length
Shorter sprints are better. 2 weeks sprint are the norm. I have said those sentences many many times. When I looked at the rally research it showed similar to team size that shorter sprints are more productive but longer sprints have higher quality. So we need to consider this in designing the length of the sprints. We also need to consider the maturity of technology and our transaction cost to determine the right sprint length (less automation = longer sprints). And then I heard an interview with a German start-up. They run 2 week sprints most of the time, but then introduce longer 4-6 weeks sprints sometimes and the reason they give is that 2 weeks is too short for real innovation. Dang. Have we not all felt that the tyranny of the 2 week sprints makes it sometimes hard to achieve something bigger, when we forcefully broke up stories to fit into the 2 weeks or struggled to get software releasable in the 2 week sprint. I still think that the consistency of the 2 weeks sprints makes many things easier and more plan-able (or perhaps it’s my German sense for order 😉). But at least I will think more consciously about sprint length from now on.
There you have it, three things I took for granted have been challenged and I am more open minded about these now. As always if you know of more sources where I can learn more, please point me to it. I will keep a much more open mind about these three dimensions of setting up teams and will consider alternative options going forward.
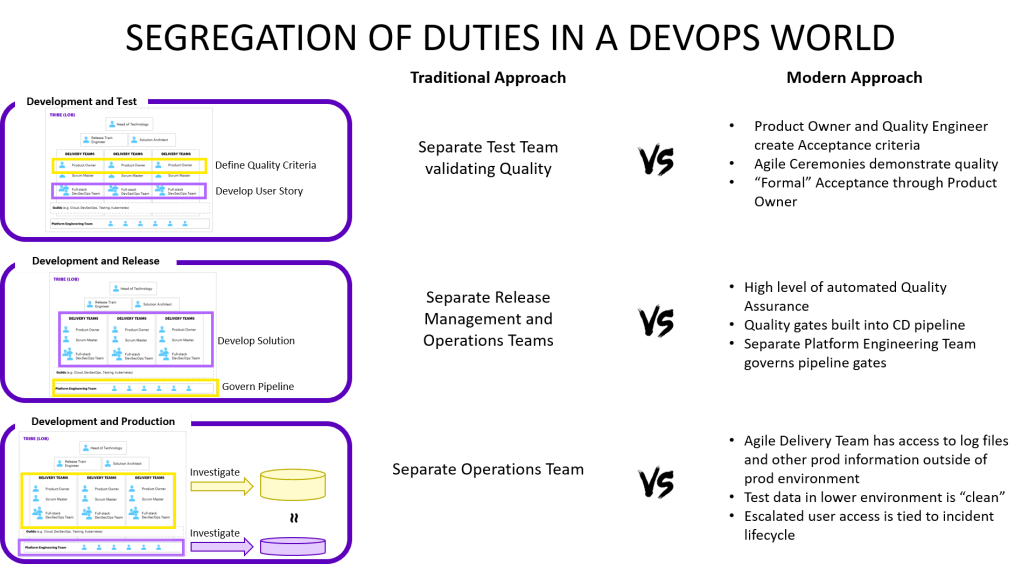
This scene could be from a spy movie: Two people enter the room where release management is coordinated for a major release. The person from the operations team takes out a folded piece of paper, looks at it and types half of the password on the keyboard. Then the person from the development team does the same for the second half and then deployment to production begins. A couple of years ago I was working for a client, where the dev and ops teams had half the password each for production. It was probably the most severe segregation of duties setup I have experienced. The topic of segregation of duties comes up frequently when organisations moving towards using DevOps ways of working. After all how can you have segregation of duties when you are breaking down all the barriers and silos?!?
Let’s explore this together in this post, but first let’s acknowledge a few things: First and foremost, I am not an auditor or lawyer. The approaches below have been accepted to different degrees by organisations I have worked with. Secondly; there are several concerns related to segregation of duties. I will cover the three most common ones that I have encountered and hopefully the principles still can be applied to further aspects accordingly. Let’s dive in!
Segregation of Development and Test
Problem statement: In a cross-functional team wouldn’t the developer “mark his own homework” if testing is done by the same team?!? To avoid this in the traditional waterfall world, a separate testing team performs an “objective” quality control.
Resolution approach: Even in a DevOps or Agile delivery team, more than one person is involved in defining, developing and testing a piece of work. The product owner or her delegate helps define the acceptance criteria. A developer writes the code to fulfill those and a quality engineer writes test automation code to validate the acceptance criteria. Additionally, team members with specific skills like penetration testing or UX test the work as well. And often business users perform additional testing. Agile ceremonies like the sprint demo and the acceptance by the product owner create additional scrutiny by someone other than the developer. In summary, segregation of duties between Dev and Test is achieved as long as people are working well across the team.
Segregation of Development and Release
Problem Statement: A developer should not be able to release software into production without independent quality check to make sure no low quality or malicious software can be deployed. Traditional approaches have the operations or release management team validate quality through inspection and governance.
Resolution approach: In a DevOps world, the teams should be able to deploy to production automatically without any intervention by another team. This is true whether we use traditional continuous delivery or more modern cloud native deployment mechanisms. But how can we create segregation of duties in those release scenarios? We leverage high levels of automated quality controls in modern release mechanisms, which means functionality, security, performance and other aspects of the software are assessed automatically before software is deployed and we can leverage this to create independent assurance. A separate group like a “Platform Engineering” team governs the quality gates of the release mechanisms, the standards for it and the access to it. This team functions as the independent assurance and all changes to the release pipeline are audited. The art here is to get the balance right so that the teams can work independently without relying on the Platform Engineering team for day-to-day changes to the quality gates, while still making sure that the quality gates are effective.
Segregation of Development and Production
Problem Statement: A developer should not be able to make changes to production or see confidential data from production, while a production engineer shouldn’t be able to use his knowledge of production to deploy malicious code that can cause harm. Traditionally access to production and non-production systems are only given to mutually exclusive development and operations teams.
Resolution approach: This is the most complicated of the three scenarios as people should get the best possible data to resolve issues, yet we want to avoid proliferation of confidential data that can lead to exploitation of such data. The mechanisms here are very contextual but the principles are similar across organisations. Give the developers access to “clean” data and logs through a mechanism that masks data. When the masked data is insufficient for analysis and resolution, then escalated access should be provided based on the incident that needs to be resolved. Automated access systems can tie the temporary access escalation to the ticket and remove it automatically once the ticket is resolved. This of course requires good hygiene of tickets as tickets which are open for a long time can create extended periods of escalated access. Contextual analysis is required to identify the exact mechanisms here, but in most organisations masked data should be able to cover most scenarios so that access to confidential data should be very limited. Root access to production systems should be very limited in any case as automation takes over traditional tasks that used to require such access hence the risk is more limited in a DevOps world. And automation also increase the auditability of changes as everything gets logged.
Summary of Segregation of Duties in a DevOps world
Hopefully this gives you a few ideas on how to approach segregation of duties in the DevOps world. Keep in mind that you achieve the best results by bringing the auditors and governance stakeholders to the table early and explore how to make their life better with these approaches as well. This should be a win-win situation, and in my experience it usually is, once you get to the bottom of what is actually the concern to address.
As I am starting back at work looking forward to an exciting 2020, I had the chance to reflect on what I have seen at my clients in 2019. The state of Agile / DevOps is so different now to a few years back, which is amazing to see for me. I thought i share my perspective. Of course this is highly subjective as it is based on the clients I spoke to and worked with. As I have spent time in Europe, Asia, Africa and Australia and across many industries, I still think this reflection might be of interest to some of you.
Before getting into the three major trends that I have seen, I want to say that I am really encouraged that the “method wars” seem to be over. Most organisations do not care so much about the specific method they use or how pure their DevOps or Agile is to some definition and rather focus on results and progress. This is very much aligned with my personal position and made it a real pleasure working with my clients last year. There was a lot less dogma than only a few years earlier. I hope this continues in 2020.
Here are my three major areas that I have worked with my clients on:
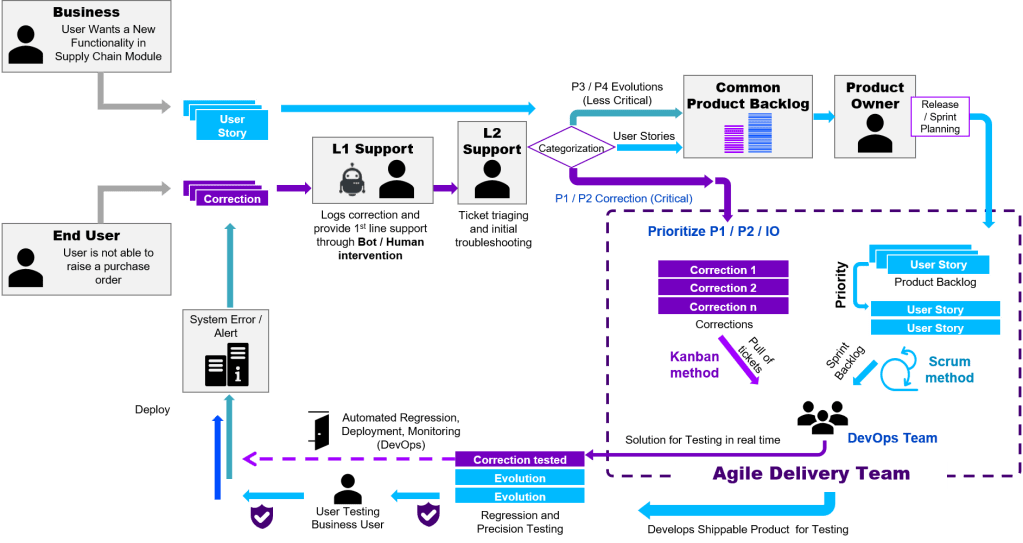
DevOps team – I spend a lot of time this year creating solutions with DevOps teams that are as self-contained as feasible. It is surprising that we don’t yet have a common understanding on how to work with a full-stack cross functional team when you have to consider:
Solution delivery/development that is somewhat plan-able and often based on Scrum
Work with the ad-hoc nature of operations tasks based on Kanban
The work that is more platform related like infrastructure, CI/CD, middleware, integration
Transformational work or work to reduce technical debt
Getting the balance right between all these things within a team or to split it out to multiple teams has been a fascinating discussion with my clients this year. I am very much looking forward to see this at large scale in 2020. Last year this idea really became mainstream and more and more clients asked for this type of delivery – finally ;-). Here is a simple systematic picture of the associated flow of work:
How to combine Dev and Ops type workflows
DevSecOps – For me security was always included in DevOps, but boy did I underestimate the magnitude of this. In 2019 I spoke to nearly all my clients about security and the new challenges in this space. I spoke a lot with security experts in the industry and learned so much more about what is happening in this sapce. I already had an appreciation for the need to secure your applications and your infrastructure (including the DevOps tools) but learning about the magnitude with which DevOps maturity increases the consumption of open source components and the speed of consumption blew my mind. Also the new thread vectors of people placing malicious code on purpose in open source components was something I hadn’t considered before. I for one will make sure all my solutions treat security as a primary concern.
Digital Decoupling – Last but not least the idea of digital decoupling. With the new IT landscapes many organisations are faced with the challenge of becoming less reliant on Mainframes and finding ways to reconfigure their packaged software ecosystems in better ways. Data has become the new answer on how to decouple systems. Being able to work on the data layer instead of having to rely on APIs, ESBs and the likes has really opened completely new ways to address this problem. The speed and agility with which you can create new functionality in this new architecture pattern is impressive. And by investing in the new stack and growing new architectures in an efficient way we can slowly get rid of the legacy applications over time. All that while creating new functionality. Gone are the days of “like for like” upgrades or technology transformations which take months and years. And of course the new architectures are being build based on Agile and DevOps ways of working enabling our transformation.
All these three trends are not completely new in 2019 but are now well and truly center stage. I will continue in 2020 to progress them with my clients and am looking forward to share with you what I learn. A super exciting year lies ahead to fully reap the benefits of these three trends coming together.
A personal note from my side on 2019, as it was an amazing year professionally for me: The year 2019 started with my book “DevOps for the Modern Enterprise” winning the best DevOps book of the year award and ended with my nomination for “Best DevOps practitioner”. What an amazing year. I look forward to 2020 and how I can help my clients best this year. I have a feeling that this year I will spend more time with a smaller number of organisations and get into a lot more day-to-day details. I am looking forward to that! Nothing is more motivating to me than to achieve results and see an organisation make progress towards better delivery of software-based solutions. And yes getting my hands dirty with the messiness of “heritage” a.k.a. legacy technologies 😉
I hope to meet many of you at a conference or at work to discuss our experiences and share what we have learned in our journeys so far.
A short while ago my team and myself ran a pilot of a DevOps simulation with our friends from G2G3. The idea of learning from a simulation (not unlike business simulations that I used to play as PC games – does anyone remember “oil imperium”?) appealed to me and I set this up for my team.
Let me be honest, I wasn’t sure what to expect. Boy was I in for a treat. Although we had a room full of people who know DevOps principles and practices we learned a lot from this one day. Let me quickly explain how the simulation runs to give you an idea.
The simulation runs in three rounds and in each round you try to make money for the company. The attendees are split into traditional roles like developer, tester, operations, service desk, product owner, scrum master etc. You get precious little guidance and off you go building features and serving customer needs. Not surprisingly you initially struggle. After the first round you talk about what to improve and have another go. And then you do the same for the third round. The real power comes from the activities being non-technical which means everyone can contribute – think of Tetris-style puzzles you have to solve to implement a feature for example. And without worrying too much about specific DevOps practices the team “discovers” better ways of working that are aligned with DevOps principles – collaboration, visual management of work, looking for patterns.
Most of the other DevOps trainings I have been part of have been pretty technical, which is great for the techies among us. But what about the project managers, the defect coordinators, the change management people, the PMO – they either have to sit through some “foreign” material in a DevOps course or often don’t even attend DevOps training. How can we then change the culture of the organisation and be inclusive of everyone. I think this simulation will get us a step closer to everyone understanding what DevOps and Agile is about and that there is a lot that can be done in addition to automation and tech practices.
I believe this simulation can be super powerful if you get your project team or leadership to attend. In a safe environment people can take on roles they don’t usually play and hence emphasize with those roles better after the simulation. The whole team will work on improvements together and it is easy to see how the learnings will bleed into their day-to-day delivery experience. If you leave the training without thinking on how you can use Kanban boards better and how to improve the quality of communication that is associated with your service management tickets I will be very surprised.
The things you experience are the power of simple things like visual management and how to improve processes by looking end-to-end. Everyone in the simulation gets the chance to redesign delivery processes and tools like the ticket system and the Kanban boards. Nothing beats experiential learning and this is the best thing I have seen for DevOps and Agile ideas. We all left the room exhausted from the full-on day, but we also agreed that even though we all knew DevOps and Agile well, we learned a lot from it in regards to practical application. Just imagine how powerful this is with a group of people who have less previous knowledge. I cannot wait to run this again!!! And I cannot wait to run a simulation with our most experienced Delivery people to see how it changes their perspective.
After running the pilot I got a group together to become trainers for this simulation as I have so many ideas on how we can use this to improve organisations and delivery. Of course I want to run this internally as frequently as possible, but I also want to make this available for our clients. If you are intrigued, reach out to me and we can see how we can get something going for you.
I am trying something new with this blog post – providing a mix of book review and a summary of what I learned about a book I really like. Waiting for Mark Schwartz to release his latest book “War and Peace and IT” I thought I re-read his earlier works. And as I was reading “The Art of Business Value” again I noticed that I am reading it with fresh eyes and that I appreciate this book even more than a few years ago.
Spoiler alert – the answer the book provides is a bit of a cop out: “…Business value is what the business values, and that is that.” But reducing this book to the final response to the question does not do it justice. The book artfully explores different angles of business value and why they are challenging when it comes to driving Agile delivery on the basis of this: ROI, NPV, Shareholder Value.
This is must read for all product owners to understand why there is not one answer to the question of business value and why Mark’s final response is unsatisfying yet completely appropriate. The book is also small enough that you don’t have to feel bad to recommend the book to the product owners you work with. I have recommended my favorite book of all time “Goedel, Escher, Bach” to many people fully knowing that only very few people would work their way through this fascinating but challenging book. “The Art of Business Value” is a book you can recommend without such thoughts on your conscience.
What I found even more useful in Mark’s book is that he explores the space around business value and three key learnings stand out for me:
That the language of Agile can lead to a new command and control paradigm – this time by the product owner or Agile coach as Only Person you can listen to (OPYCLT)
That the product owner as interface to the business requires a special kind of organisation and having X-teams are a better approach
That the bureaucracy and governance we encounter is codified business value of the past
Let’s explore each of these a little further:
Agile as a new command and control paradigm
This one hits close to home. For a while I have been complaining about the Agile coaches out there who evangelise their methods without being able to explain why calling something a “PBI” is better than “User Story” or why we will only provide documentation in code. Mark adds another interesting dimension to this, if the product owner is the Only Person You Can Listen To for the team then how is this different to the project manager assigning work. Mark argues in a similar vein that the prescription of technical practices is a similar command and control rule – I recently spoke to an organisation that does not do automated testing and rather does production monitoring in full knowledge that they can respond quickly enough if something breaks. So I think we need to all be vigilant to not let Agile drift into just another command and control world this time run by the agilists instead of the project managers.
Product Owner vs. X-Team
In traditional Agile thinking the product owner represents the business and he presents the business problems to be solved to the Agile team which go off and solve them. Mark compares this with a loosely coupled system where the details of implementation is up to the team as long as they fulfil the contract that the product owner has made with the business. I am with Mark that this too simplified. We have plenty of experience that shows that the product owner needs help to manage the backlog and to work with the rest of the business. Mark introduces a new term “X-Team” from another book as guiding principles that teams need to work internally and externally. It is amazing how much more productive teams can be when they have rich context. For one of my Agile teams we arranged recordings of customer calls and visits to call centers so that the team got a better understanding of the business problem rather than relying on the product owner. The levels of innovation immediately increased when we started doing this.
The value of bureaucracy
This one is probably the one that requires the most consideration and came out of nowhere for me in re-reading the book. I think I had dismissed this point last time I read it. Mark argues that the processes you encounter were at some stage codified business value in many cases. And that we would be at risk of losing tacit knowledge of the value if we just throw it all out. Rather we should understand what the underlying value was and whether or not it is still applicable. You can then decide whether there is an alternative way to create that value or whether you continue with the established process. A good example is transparency as a value which might require you to do certain things that might not on first view provide value of itself like additional documentation or reviews.
There you go – I really enjoyed the second time I read his book and hope you will too.
Organisational transformations have been part of organisational life for many years. There are reorganisations, big IT transformations and nowadays Agile, Cloud, Digital or DevOps transformations. These transformations used to follow a familiar pattern: an organisation is going through a major transformation and invests significant amounts of money over a 3-5 year horizon into the transformation. At the end of the transformation when the “end-state” was achieved, the level of investment got reduced and focus shifted to stabilisation and cost reduction. Over time the requirements changed more than the current level of investment allowed us to adapt for. Technical debt and the gap between needs and system functionality increased until this reached a level that required significant reinvestment or a new transformation to the next trend.
The cycle repeated every few years. While far from ideal it seemed to work okay, it was good business for technology companies and consultancies, it provided a level of comfort for organisations as they executed their 3-5 year roadmaps of transformation. The duration was not really a problem as the environment changed slowly enough for organisations to catch-up with each cycle. The level of change in the environment has increased and competitors are increasingly coming from digital startups that move very quickly. This means that the traditional transformation cycle is too slow to react. We cannot afford 3-5 year cycles any longer and rather need to create an organisational capability to continuously adapt to the environment. If you do one more transformation in your organisation it needs to be the anti-transformation transformation. The idea of this transformation is to transform not with a specific technical capability in mind but rather to transform to an ever improving, a learning organisation and to build the organisational capability that allows you to drive this ongoing process in a sustainable pace and process.
There are obviously a few things different with this transformation and the most obvious yet confusing thing is that there is no end-state. There is no end-state technology architecture, there is no end-state organisational structure and there is no end-state delivery methodology. But if there is no end-state how do we know when we are done? This is the bad news, we will never be done. We have to create capabilities that make it easier and easier to adapt incrementally and we need mechanisms to guide each improvement even in the absence of an end-state.
Having this discussion with my clients makes me feel like a GP who is telling the patient that is coming to the office that there is no pill that I can give to reduce his blood pressure and shortness of breath, but rather that the patient needs to eat healthier and do more sports. It is not going to be easy and each day will present a new challenge. Furthermore as his consultant I cannot do this work for him, I can only guide and support, but the patient has to do a lot of the work himself. The exact same is true for organisations neither Cloud, Robotic Process Automation, AI or any other technology will magically solve the problems. We need our organisations to change to a healthier lifestyle to remain fit and survive.
Enough of the analogy, but I hope you get the point. So what can we do to guide the anti-transformation transformation? First of all our view of technology architecture needs to change, as highlighted in this blog post there are 3 architectures we are dealing with and each one of them needs to be adaptable: our business systems architecture, our IT tools architecture and our QA and data architecture. We also need to have a guiding system to show us where our technical debt is and where systems are highly coupled – these need to reduce to remain adaptable. Last but not least we need to find ways that allow us to continue to evolve organisational structure and methodology in a way that does not disrupt the business – it is not about moving from the Spotify model to SAFe or vice versa, but rather its about running small experiments with your own contextual methodology or org structure to be able to evolve and continuously improve. If you are still in the beginnings of the anti-transformation then you might want to adopt one of the more common methodology frameworks to get yourself started, but if in 2-3 years you are either still doing the same things or feel the need to adopt another model then you have a problem. Neither of those two extremes should be correct, you should feel like you are working with a methodology and org structure that is truly your own and that has been optimized for your context over time.
One last thing to note – larger disruptions in business or technology will still cause more challenging needs for change and require you to increase investment, but it should not require another transformation. It should rather require a larger incremental change that is easier to manage because we decoupled our architectures and methods.
The transformation is dead, long live the anti-transformation transformation.
I have been a technology architect for a long time and have worked with many different technologies. And there is something satisfying about coming up with “the architecture solution” for a business problem. The ideal end-state that once implemented will be perfect.
Unfortunately I had to come to the realization that this is not true. There is no end-state architecture anymore and there never was. All those diagrams I drew with the name end-state in it – they are all obsolete by now.
Knowing that architecture will continue to evolve (just look at the evolution of the architecture of Amazon (or many other internet companies) over the years) means as architects we need to think differently about architecture. We need to build architectures that before even implemented are already considering how parts will be replaced in the future. No stone will remain unturned over time no matter how good they seem at the moment. So rather than spending time on defining the end-state we need to spend more time understanding and defining the right principles of architecture for our organisations and manage the evolution of the architecture – how technical debt is paid down and systems are being decoupled for the eventual replacement.
This would be difficult if we had to deal just with the architecture of business systems. Reality is that in the current IT world we have to deal with three different architectures: the business systems architecture, the IT tools architecture and the QA and Data architecture.
Let’s quickly define these:
Business Systems Architecture – this is usually well defined in organisations. How do your CRM, ERP and billing systems work together to achieve business outcomes
IT Tools architecture – this is the architecture of all your tools that make IT delivery possible: configuration management, container management, deployment, defect management, Agile lifecycle, etc
QA and Data architecture – how do we validate that systems are working correctly both in production and in new development and how is data flowing across systems and environments
All three of these architectures need to be managed with the same rigor and focus on continuous evolution as the business systems architecture. This will make the job of architects a little bit more complicated. At the moment I see many organisations not having architects focused on all three architectures as they are not perceived as being of similar importance.
Let me give you some examples from my past to highlight why that is foolish:
One of my clients was already pretty mature in their automation so that all deployments to production were fully automated. Unfortunately their deployment architecture was basically a single Jenkins server that was manually maintained. When this server was wiped out by mistake it took weeks to get the capability back to deploy to production – in the mean time very risky manual deployments had to be performed by people who had not done this in months
Another client of mine had built a test automation framework that was too tightly coupled so that it took a lot of effort to replace one of the components and maintenance had become so expensive that they had stopped using it – ultimately there was too much technical debt in the tests and the QA and data architecture
The answer of course is that all three architectures need to be managed by architects in similar ways (e.g. failover and availability need to be considers for IT tools and QA tools too) and that the principles of decoupling and continuous evolution need to be aspects of all three.
The architect function is one that will see a lot of change as we come to terms with managing three interconnected architectures and the evolving nature of architecture. But I think it will make the job more interesting and will allow architectures to climb down from the proverbial ivory tower to engage with the Agile delivery teams in a more meaningful way.
Its already over again – the annual get together of the brightest DevOps minds (well the brightest who could make it to Vegas). And in this instance I want to make sure that what happens in Vegas, does not stay in Vegas by sharing my highlights with all of you. It was a great event with a slightly higher focus on operations than last time.
The four trends that I picked up on:
Self service operations are considered an good answer to the “DevOps Team” problem
The prevalence of Dunning Kruger (Link) when it comes to self-assessments -> We are “DevOps”, we use the “cloud”,…
Minimum Viable Compliance as a new term
DevOps for AI – I did not see much AI for DevOps yet, perhaps next time
This year the conference focused much more on operations which is great, for next year I hope that we bring in some of the end-to-end business stories. How have we used DevOps practices to drive business – thinks like instrumentalization of software features to understand the business impact.
The top 3 talks
Andrew Clay Shafer
Andrew spoke in his typical eccentric style (with tie on his head) about Digital Transformations and doing DevOps. He made it clear that there is no real end to this transformation and compared it with getting fit (something he took on successfully since the beginning of the year). All the external help you can get will not make you fit, it’s the work you put in yourself. The same is true for this DevOps/Digital transformation. He also made a good point that some message can be dangerous if they are given before the recipients are ready.
J Paul Reed
I admit that I went into “5 dirty words about CI” expecting a talk about Continuous Integration like many others , something John humorously took on in the beginning. The talk focused on Continuous Improvement instead and stood out for me. Key learnings:
Root causes are a social construct for the point where we stop looking further, more appropriately we should call those “proximate causes”
A great story from Amazon, who used an outage caused by “human error” to look for the weaknesses in the systems rather than finding fault with the person who made a mistake
That incidents are not deterministic – there are many parallel universes where the incident might not have happened in the same circumstances, our systems are too complex to be deterministic. The Swiss Cheese model to analyse incidents was a great take away for me.
Human error is not the cause, it’s the effect. It’s the start of the investigation.
Damon Edwards
Okay, okay he usually is in my top list of talks because I like his style and approach. This time he told a great case study of how all the new fancy technologies and techniques did not prevent the opps problems. Which was a) funny and b) educational to move us away from all the techno-optimism. He then described the self-service operations model which I prefer myself as well, so this was good to see discussed, which is also called out in the latest puppet state of DevOps report.
Some other nuggets from other talks
Courtney Kissler
First mention of “Minimum Viable Compliance”
I loved the phrases “Geriatric stack” and “PTSD caused by legacy apps”
Great story on how compliance can calculate negative ROI to justify investment
Scott Prugh
Great case study where he showed the results over the years
Showing how Agile and DevOps work together to achieve huge results
Aligning teams to Value streams not projects and even using the platform as a product with product owner
Some interesting aspects on lean portfolio management that is run through several “tanks” like sharktank
I loved the metric – “% of things releases outside of release cycle”
Jeffrey Snover
Super inspiring to hear from someone who stood up for what he believed in and that careers can be a bit like snakes and ladders (it took him 5 years to come back from a demotion)
Insightful to hear about organisations and/or leaders having a list of people who are moving the company forward and of course those are the people that get well rewarded
How transitions transformations can push your career – introducing the terms stair job vs elevator jobs
Loved the point that when you are really good at something that doesn’t matter anymore that it will be bad for you (either as organisation or in your career) – great example from DEC which was excellent at something that didn’t matter anymore a and missed the move from vertical integrated to horizontal systems
He made a point that he believes the pendelum is swinging back to vertical integrated (like Azure and AWS)
“Build what differentiates you, buy what doesn’t”
Thorsten Volk
Reiterated the point I have heard a few times now that AI is still similar to the 90s just more accessible and powerful
Understand what AI and human understanding is good for and when to use what
Start with a narrow problem and extend it once you have a useful answer
Treat AI as code – Parameters, training set, data transformation pipeline, etc
Use public data – there is heaps that you can use to teach your algorithms
AI is a virtual reality as you can only see what is in the data and that data can be biased
Mik Kersten
He introduced his new framework to help with the transition from project to product which is described in his new book, which was available at the conference for the first time (I will review it in a blog post in due course)
Rob England
How some of the new material in the DevOps world has forgotten the old and sometimes is even reinventing it
Interesting anecdote that the SRE book comes to the conclusion that key metric is unplanned downtime – something the ITSM community has already know
How DevOps has not covered everything that ITSM covered like user training/Desktop management,… – there is some benefit in review the more rigorous material from ITIL
Gave us hope that ITIL 4 will be more relevant and easier to consume vs ITIL 3 being a bit of mixed bag
Jez Humble, Nicole Forsgren
Only 22% of people who say that they use the cloud are following the 5 characteristics of NIST – most hands went down at “OnDemand Self Service”
Cornelia Davies
Difference between functional and imperative programming
Why functional programming allows us to do get systems to do more for us and are less error prone because there is no state embedded
The term “Repave environments” – refreshing every part of the environment which we should do regularly
Introduced the concept of “Sidecars” – a container next to another container in a Kubernetes pod that deals with cross cutting concerns like security
Another brilliant conference is over and I am already looking forward to next year.
As Agilists we keep using the Agile manifesto and are pretty much beyond questioning the exact words on the page. One key one is:
Working Software over comprehensive documentation
And over the years we had the arguments that this does not mean that there is no documentation, what exactly the definition of working software is and many other aspects of this. Yet I failed to pick up on a very important nuance for all those years.
The other day I was running an Agile training and someone with less of an IT background called out to me that she disagrees with the statement “working software over comprehensive documentation”. I was shocked initially until she explained that working software means terribly little when no one uses it (for example due to poor documentation or change communication) or if the software does not solve a business problem.
Wow – how had I not noticed this clear miss before. Of course, we are not about just building software and the Agile manifesto came from people who were thinking about creating software in a better way. But more than decade after I started to run Agile trainings, why had I never noticed this clear gap in the manifesto for our modern context.
A few weeks earlier I was at an Agile conference in Germany and someone spoke about Agility rather than Agile and pointed out how much of the language in the Agile principles behind the manifest are software specific (e.g. “The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.”) How have we not updated this material to be more relevant by changing all the wording to be inclusive of business and other parts of the organisation that need to enable success? See below for references to software development in more than half of the principles.
Of course, the manifesto has its relevance as historic document, but whenever we talk about it, it is worthwhile calling out that we do have a broader understanding of this now which goes way beyond IT and software development. I for one will call this out more clearly whenever I run training going forward. We are using Agile to solve business problems and creating better software is only a small part of the solution. Thank you Jane for calling out a blind spot that I have had for years!
UPDATE: Thanks to Phil i found this tweet which discusses a solution:






 I am trying something new with this blog post – providing a mix of book review and a summary of what I learned about a book I really like. Waiting for Mark Schwartz to release his latest book “War and Peace and IT” I thought I re-read his earlier works. And as I was reading “The Art of Business Value” again I noticed that I am reading it with fresh eyes and that I appreciate this book even more than a few years ago.
I am trying something new with this blog post – providing a mix of book review and a summary of what I learned about a book I really like. Waiting for Mark Schwartz to release his latest book “War and Peace and IT” I thought I re-read his earlier works. And as I was reading “The Art of Business Value” again I noticed that I am reading it with fresh eyes and that I appreciate this book even more than a few years ago. There are obviously a few things different with this transformation and the most obvious yet confusing thing is that there is no end-state. There is no end-state technology architecture, there is no end-state organisational structure and there is no end-state delivery methodology. But if there is no end-state how do we know when we are done? This is the bad news, we will never be done. We have to create capabilities that make it easier and easier to adapt incrementally and we need mechanisms to guide each improvement even in the absence of an end-state.
There are obviously a few things different with this transformation and the most obvious yet confusing thing is that there is no end-state. There is no end-state technology architecture, there is no end-state organisational structure and there is no end-state delivery methodology. But if there is no end-state how do we know when we are done? This is the bad news, we will never be done. We have to create capabilities that make it easier and easier to adapt incrementally and we need mechanisms to guide each improvement even in the absence of an end-state. I have been a technology architect for a long time and have worked with many different technologies. And there is something satisfying about coming up with “the architecture solution” for a business problem. The ideal end-state that once implemented will be perfect.
I have been a technology architect for a long time and have worked with many different technologies. And there is something satisfying about coming up with “the architecture solution” for a business problem. The ideal end-state that once implemented will be perfect. Its already over again – the annual get together of the brightest DevOps minds (well the brightest who could make it to Vegas). And in this instance I want to make sure that what happens in Vegas, does not stay in Vegas by sharing my highlights with all of you. It was a great event with a slightly higher focus on operations than last time.
Its already over again – the annual get together of the brightest DevOps minds (well the brightest who could make it to Vegas). And in this instance I want to make sure that what happens in Vegas, does not stay in Vegas by sharing my highlights with all of you. It was a great event with a slightly higher focus on operations than last time.

