The other day I was in one of those long status review meetings that everyone pretends is productive. Everybody was saying sensible things and somehow we were still heading for trouble. The risk register was full. The status report was mostly green, with a tasteful amount of amber and a bit of red to signal realism.

What struck me wasn’t that the team had ignored risk. Quite the opposite. They had probabilities, impact scores, owners, dates. The mechanics were all there. But when I asked the simple question — what is the overall risk position of this program? — nobody could really answer it. We had plenty of detail, but very little clarity.
I have spent most of my professional life on large delivery and transformation programs, and one thing has changed quite a lot in how I think about status. Early on, I mostly looked at progress against tasks (and I still do as people who have worked for me can painfully attest to given the level of detail I ask for). These days I care far more about outcome measures and risk.
Of course the world has changed too. When I started, everything was waterfall and on-premise. Now it is Agile, cloud, digital and AI. But the bigger shift in mindset for me is this: on complex programs, progress reporting on its own just does not tell you enough to be successful.
I have written before about measures and scorecards, so I won’t go back over that here. What I want to focus on in this post is one lens I ask my teams to include in status reporting: major risk burndown, paired with our contingency position regarding the portfolio risks.
Burn down the most concerning risks early
I still like detailed reporting on deliverables and milestones. But on complex programs that is only part of the picture. What I really want to know is this: what are the few things that could seriously derail us, and what are we doing to reduce that exposure?
One thing I have learned, repeatedly and occasionally the hard way, is that large programs rarely fail because one team missed a task on a plan. They fail at the connection points: dependencies, handoffs, integration points, environments, external parties.
The good news is that many of these failure points are visible early. And once you can see them, you can define the activities that will actually burn that risk down.
In my experience, the usual suspects are not that mysterious. They tend to look something like this:
- standing up new environments or cloud landing zones
- third-party delivery dependencies
- data complexity or sheer data volume
- system performance
- integration across systems
There are different ways to identify these risk areas up front. One technique I like is the pre-mortem, popularised by Gary Klein: assume the program has gone badly wrong, then work backwards and ask why.
Once you know the major risks, the next step is straightforward. For each one, define the concrete actions that reduce either its likelihood or its impact. As those actions complete, the risk comes down. That gives you something far more useful than generic “red amber green” commentary: a visible burn-down of uncertainty that you can quantify.
Take a simple example. Say one of your biggest risks is that a third-party system will not integrate properly once delivered. The team assesses that as 25% of the program’s major risk exposure.
You then break the burn-down into concrete steps: agreed interface specification, test stubs, first code drop, functional test pass, performance test pass. If you weight those evenly, each completed step burns down one fifth of that risk. In this example, that means each one reduces overall major risk exposure by 5%.
It does not need to be overly precise or scientific to be useful. It just needs to be explicit enough that the team can see whether uncertainty is actually coming down.
If you are worried about how precise those percentages are, I would not get too hung up on it. In my experience, relative weighting is usually enough. I have used the rough equivalent of planning poker for this: get individual views from the team, compare the outliers, then talk it through until you reach a workable level of consensus. You are not trying to produce actuarial science here. You are trying to make uncertainty visible enough to manage.
Here is an example schedule for one of the major risks in one of my programs, you can see the 9 burndown actions as little circles. Each would have specific acceptance criteria and a way to measure progress towards it.
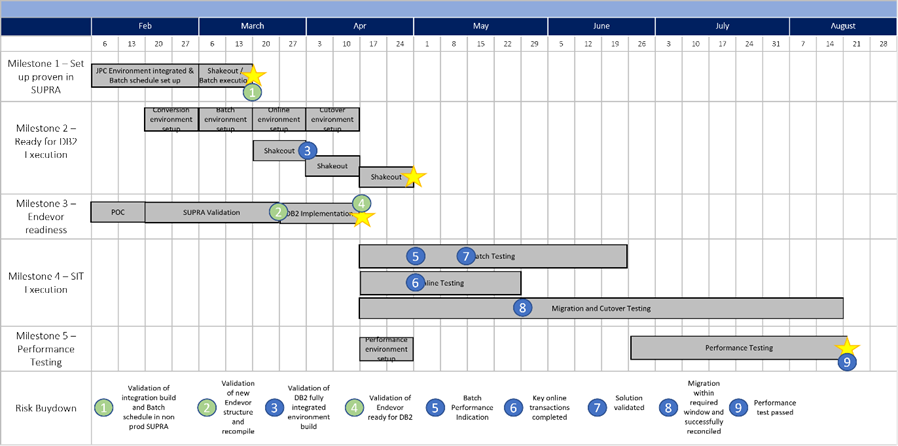
This is also one of the things I have always liked most about Agile, at least when people practice it rather than just put it on slides: do the risky thing first.
If something might derail the program, why would you leave it until later? Why would you optimise for neat sequencing when the real problem is uncertainty?
Yet enterprises still do this all the time. We reward predictability over adaptability. We like getting “runs on the board.” We often prefer the appearance of commitment over the economics of resilience.
So if you are betting on something important — a new technology, a big AI-driven productivity gain, a performance improvement, a vendor promise — find a way to test that early. Pull the uncertainty forward. Do not wait politely for reality to reveal itself on your most expensive critical path.
Contingency is how you fund the remaining uncertainty
Major risk burndown is only half the picture. Most programs also carry a long tail of smaller risks: things that are annoying, expensive, and real, but not individually catastrophic.
For those, I find it useful to assign contingency values. In other words: if this risk materialises, what would it likely cost us in money, time or both? That gives you a portfolio view of exposure, not just a list of isolated issues.
Not all risks deserve the same treatment. Some need to be actively burned down because, if they hit, the whole plan changes shape. Others are better handled through contingency: extra money, extra time, extra help, or a workaround.
And of course, if the total value of all identified risks comes to 10 million dollars, it rarely makes sense to hold the full 10 million in contingency. Not every risk will materialise. So organisations make a judgment based on risk appetite, delivery context and portfolio profile. In my experience, holding somewhere between 25% and 75% of the total quantified exposure can be entirely reasonable.
Once you have decided how you will calculate contingency, there are really two disciplines to maintain. First, track the individual risks in the normal way. Second, use major project milestones to reassess how much contingency you still need. As uncertainty comes down, the contingency position should change too.
You can see below what this can look like for a project with 30M contingency:
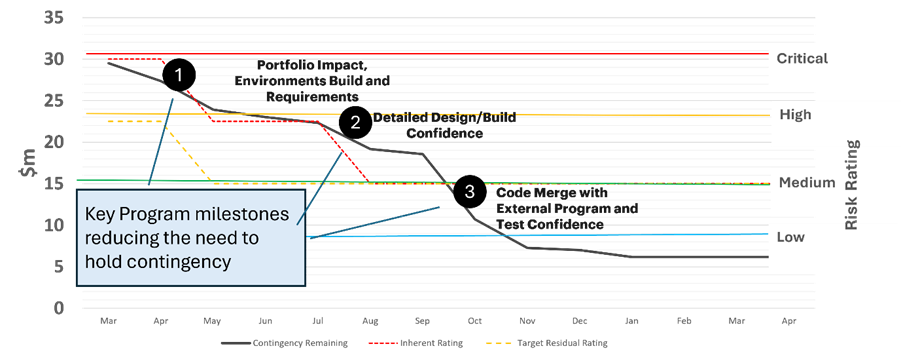
I am increasingly convinced that one of the best indicators of delivery maturity is not how well a team identifies risks, but how honestly it funds uncertainty and tracks progress against it.
We still too often treat contingency as a sign of weak planning. I think the opposite is usually true. Very often it is a sign that somebody understands the shape of complex work.
There is a lot more to say about contingency management and maintaining optionality in delivery and I suspect I will come back to it.
But the broad idea here is simple enough. On complex programs, progress reporting is necessary, but it is nowhere near sufficient. I want to know which risks matter most, what we are doing to reduce them, and how we are managing the uncertainty that remains.
Even with all of that in place, programs still go wrong sometimes. I have a few scars to prove that – ask me over a beer or whisky about it. But I would still rather face the risky things early than discover too late that all the tidy progress reports in the world were describing motion rather than control.
