“Big, centralised Test Centres of Excellence are a thing of the past” – Forrester 2013
Agile clearly took the IT industry by storm. In my early days trying to bring Agile to projects a few years back I had to explain even what Agile means. Nowadays pretty much all my clients are using some kind of Agile somewhere in their organisation. Now we see the challenges of hot to support delivery in an Agile fashion and how to optimise for speed to market. One common obstacle is duration and effort for testing. Too many organisations are still relying on large scale manual inspection instead of having an optimised and automated approach to testing. Of course in most cases not everything can be automated, but it is far more common to see too little automation than to see too much automation.
“Quality comes not from inspection, but from improvement of the production process.“ – Dr W. Edward Deming
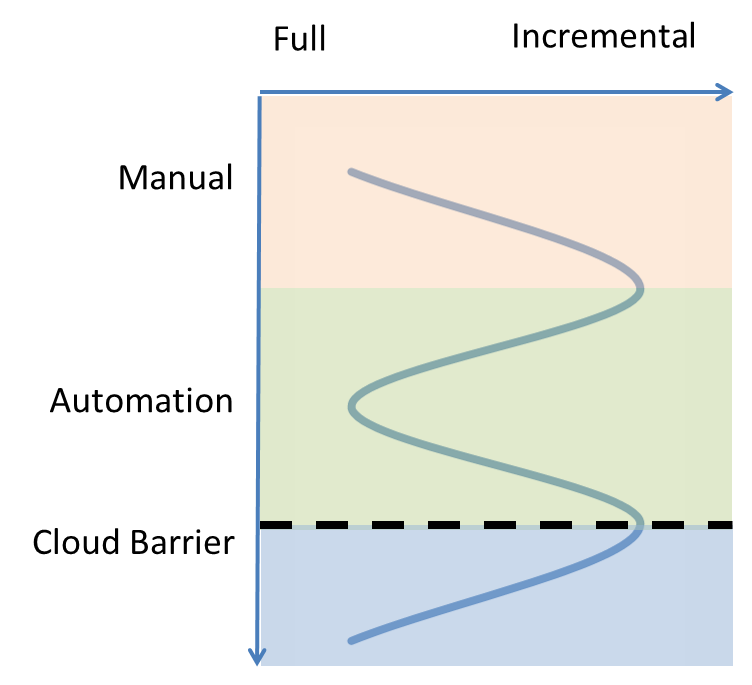
 The above picture illustrates the shift that is required to really support speed to market. Quality needs to be built into the development process from the beginning and every opportunity for early feedback should be used to avoid the late detection from manual inspection. There is so much good evidence showing that the temporal delay for finding defects is very costly. People don’t necessarily still remember what exactly they were thinking when they made a specific change a few weeks ago. Or worse the fix might even be given to someone completely different who first has to understand the context of the piece of code that he is trying to fix.
The above picture illustrates the shift that is required to really support speed to market. Quality needs to be built into the development process from the beginning and every opportunity for early feedback should be used to avoid the late detection from manual inspection. There is so much good evidence showing that the temporal delay for finding defects is very costly. People don’t necessarily still remember what exactly they were thinking when they made a specific change a few weeks ago. Or worse the fix might even be given to someone completely different who first has to understand the context of the piece of code that he is trying to fix.
For many organisation this provides a challenge as most testing is organised centrally from a Testing Center of Excellence. This needs to change.
 Rather than having this large group of testers who are centrally organised, we need people with quality focus embedded in our Agile teams. The manual tester who just executes test scripts is a thing of the past mostly. The new roles require people who understand the business context and can come up with test strategies that minimise the risk in our application. Those test experts are the kind of people who look both ways on a one way street, they just think differently to other people and hence have a very specific mindset that we need.
Rather than having this large group of testers who are centrally organised, we need people with quality focus embedded in our Agile teams. The manual tester who just executes test scripts is a thing of the past mostly. The new roles require people who understand the business context and can come up with test strategies that minimise the risk in our application. Those test experts are the kind of people who look both ways on a one way street, they just think differently to other people and hence have a very specific mindset that we need.
“Good testers are the kind of people who look both ways before crossing a one-way street”
Besides creating test strategies they will also look after exploratory testing which finds things outside of the usual boundaries. And then we need the test automation developers who should also be embedded in the Agile teams. This decentralising of quality experts does not mean that there is no need for a central function. Test Automation requires a technical framework that should be owned by the central function. Additionally the central function should make sure that lessons learned and other experiences are being shared and that the profession of Automation Developers and Test strategists and Exploratory Testers continue to evolve. Providing networking opportunities, knowledge sharing session and more formal guidance on how to embed quality as early as possible in the development process should be the new focus. This also means to collaborate with the development and engineering teams on coding standards, on the way static code analysis is being used and what can be covered by automated unit testing. On the most basic level it is a shift from testing to quality engineering.
The nature of the central function will shift from a Testing Center of Excellence to a Center of Quality Engineering. Will this be difficult and transformation? Yes it will be and I will leave you with this thought that all TCOE practitioners (and testers for that matter) should take to heart:
“It is not necessary to change. Survival is not mandatory.“ – Dr. W. Edward Deming










{kind=link}