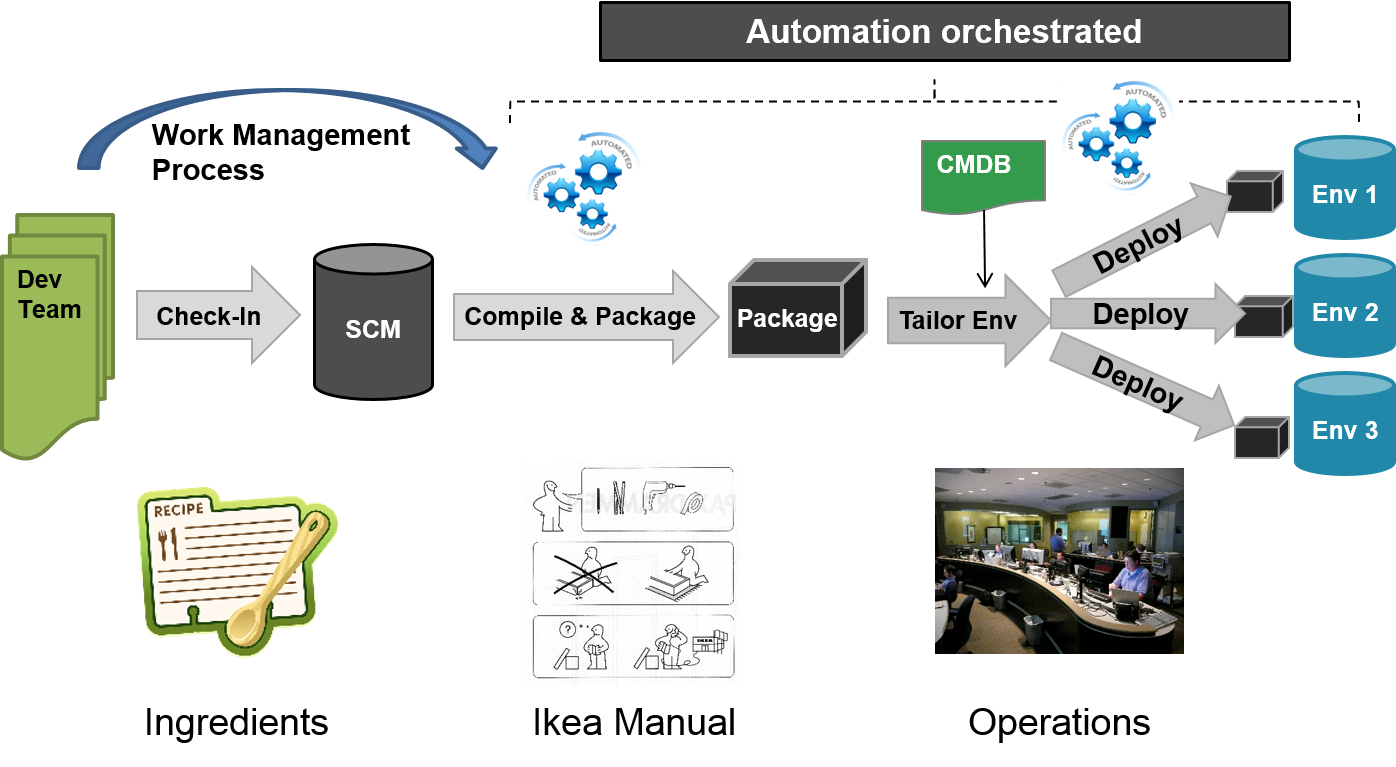
The theme of conference was so nicely summarised by Jody Mulkey from TicketMaster “DevOps is not a technology problem” already in the morning of Day 1. Most talks covered the cultural aspects of DevOps and what good looks like and what it takes to transform the organisational culture. Some of my takeaways to try at home to shift culture are:
The theme of conference was so nicely summarised by Jody Mulkey from TicketMaster “DevOps is not a technology problem” already in the morning of Day 1. Most talks covered the cultural aspects of DevOps and what good looks like and what it takes to transform the organisational culture. Some of my takeaways to try at home to shift culture are:
- Blameless Culture
- Value Stream mapping
- Minimal Viable process
- “Red Tape Removal teams”
- Internal Conferences/Hack Days and other avenues for informal learning
- ChatOps as communication channel
The other topic that came up again and again was: Metrics. Everyone is looking for ways to measure progress and justify improvement investment. This certainly validated the efforts of a working group before the conference. The working group put together a paper on measuring DevOps which you can get access to here http://devopsenterprise.io/media/DOES_forum_metrics_102015.pdf I was part of the team and have to thank everyone involved for a great experience and amazing support from the team at IT Revolution.
As part of the Unconference there was a very lively discussion about metrics. I think there was some level of consensus about a few points:
- There is not one measure to rule them all, you need multiple dimensions for steerage
- The metrics in focus shift over time
- You should use the scientific method and drive improvements through hypothesis and validation
There was consensus that DevOps is not a goal – “are we there yet?” is not a valid question. Jason Cox summarised it nicely in his talk: “Keep moving forward with curiosity”. That is the spirit of the conference and the overall DevOps movement.
Technology wise – I think the practice/tool that stuck with me most was ChatOps. This seems to have broken into many organisations and is a tool to change culture and the way collaboration works.
Some highlight talks for me were – and there were so many more (!):
Jason Cox – Disney: Okay as a geek it would always be hard to trump a talk that is full of Star Wars references and shows the latest trailer. But besides this he is just great in giving insights into the Disney org and how to leverage the unique company culture for the DevOps movement.
Adrian Cockcroft – Battery Ventures: A fantastic talk about systems thinking applied to organisations. Fascinating insights into the cultures of companies like Netflix. So many ideas in the talk that it requires hearing it a few times to catch it all.
Damon Edwards – DTO solutions: This talk brought everything together what we heard throughout the conference. The summary slide shows the learning organisation, the measures, the idea of a journey not a goal to reach:
Jez Humble: This talk one of the most interesting metrics for DevOps progress and success: Number of manhours required outside of business hours for a production deployment – the goal needs to be 0. Overall great talk about the architecture concerns for DevOps. Its an unsung truth that architecture plays a huge role in DevOps and is difficult to change.
Steve Spear – High Velocity Edge: About leading a learning organisation. He demonstrate with examples very well that leaders have to have the courage to lead from the front in regards to learning and acknowledging that they don’t know everything. The other takeaway was the rigorous adoption of the scientific method in all aspects of the organisation and the example of Toyota showcased how such an organisation destroys the competition.
Josh Corman & John Willis: An insightful talk about vulnerabilities in software and the importance of taking this serious, not just to save money, but to save lifes!
Topo Pal – Capital One: Topo’s point of Capital One contributing their tools to open source for the community was a powerful statement. We can all benefit from being more open and sharing more with the community. Thank you Topo.
Rosalind Radcliff – IBM: Educating us on what is possible with Mainframe. One of the few talks about “legacy” and really insightful that modern delivery methods are absolutely possible with the mainframe.
Mark Rendell – Accenture: Talking about the role platform applications play in solving the organisational structure challenge of scaling DevOps.
What did I get most value out of you wonder?
100% the discussions with people in the hallway, with fellow speakers, with all the people who are on the journey with me. Looking forward to make the next steps together and share our stories again next year.
Favourite Quotes:
- “Motion != Work” Jason Cox & Jez Humble
- “We cant copy Netflix because it has all those superstar engineers, we don’t have the people” Fortune 100 CTO —- “We hired them from you, and got out of their way” Adrian Cockcroft
- You are either building a learning organization…or you are losing to someone who is – Andrew Clay Shafer requoted in USPTO session
- “We are open sourcing our tools because it is the right thing to do.” Topo Pal, Capital One
- “Buoys, not boundaries.” Ralph Loura, HP Enterprise
- “Too much planning means you miss out on opportunities to learn and adjust.” Gary Gruver, co-author, “Leading the Transformation”
- “We have horrible hygiene in our software supply chain” – Josh Corman, Sonatype
- “I am in this (DevOps) to save lives” – Josh Corman, Sonatype
- “We had Schroedinger releases – until it was in production we didn’t know whether it was dead or not” – Elisabeth Hendrickson
- “Project based teams accrue technical debt, product or platform based teams pay it down” – Adrian Cockcroft
What I want to see more of next year:
- People talking about managing vendors and systems integrators
- Experiences with learning cultures and how the experiments went
- Even more discussion on bridging the chasm to the organisational majority
Cultural references/Running Gags:
- Lots of Star Wars references – aren’t we all looking forward to Christmas? How fitting we had Jason speak again.
- Volkswagen gags were also popular